2026 年 4 月 24 日,深度求索(DeepSeek)正式宣布其全新一代大模型系列DeepSeek-V4 预览版全球上线,并同步完成全量开源。该系列模型通过底层架构的突破性创新,实现了 1M(一百万字)超长上下文能力的全服务标准化,在 Agent 智能体协作、世界知识储备、逻辑推理等核心性能上,全面达到国内及开源领域的领先水平,实现了对顶级闭源模型的全面追赶。
双版本矩阵布局,覆盖全场景需求
DeepSeek-V4 针对不同应用场景与算力需求,打造了两大核心规格,形成「极致性能 + 极致性价比」的双线布局,精准匹配企业级与轻量化场景的差异化需求。
DeepSeek-V4-Pro:性能直击全球顶级闭源模型
- 核心规格:1.6T 总参数量,激活参数量 49B
- 核心优势:
- 在 Agentic Coding 专项评测中拿下开源领域最佳成绩,代码交付质量无限接近 Opus4.6;
- 在数学推理、STEM 学科测评、高难度竞赛代码等核心基准测试中,全面超越所有已公开评测的开源模型,跻身世界顶级推理性能梯队。
DeepSeek-V4-Flash:主打极致普惠的高性价比方案
- 核心规格:284B 总参数量,激活参数量 13B
- 核心优势:
- 世界知识储备略逊于 Pro 版本,但在常规任务的推理能力、Agent 智能体表现上与 Pro 版本旗鼓相当;
- 大幅降低推理算力门槛,可为用户提供更快捷、更低成本的 API 服务,实现大模型能力的普惠落地。
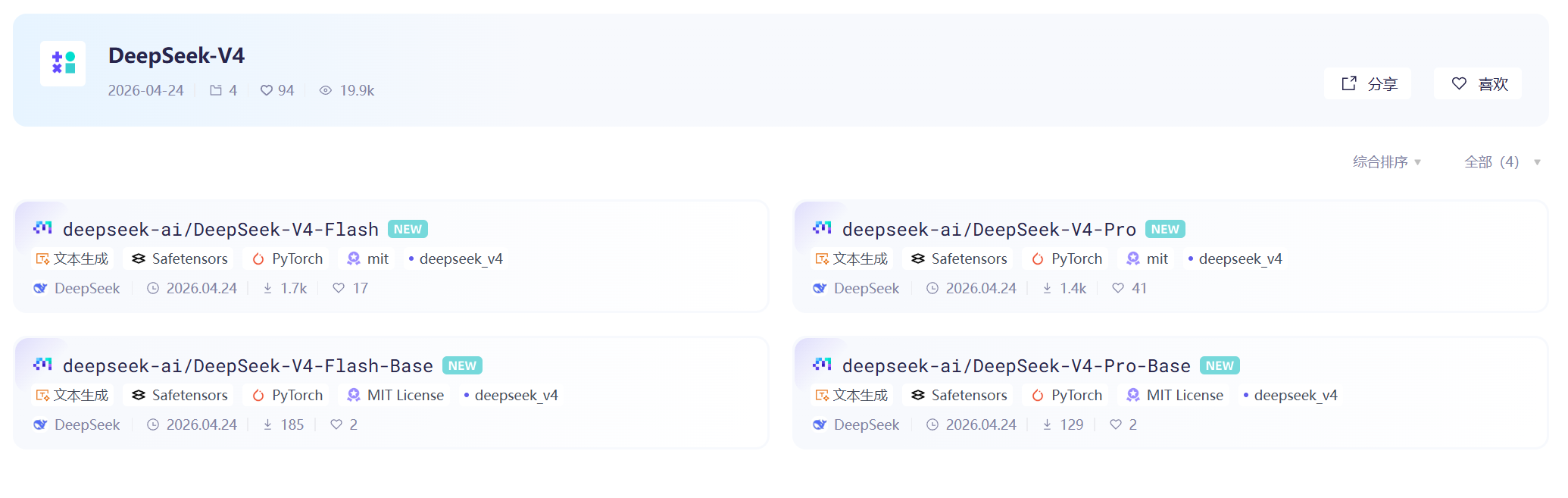
目前,两大版本的 Base 基础版与对话版均已同步上架 Hugging Face 与魔搭(ModelScope)社区开源平台。
核心技术突破:DSA 稀疏注意力机制,实现长上下文能力普惠
DeepSeek-V4 最核心的创新,是开创性地采用了DSA 稀疏注意力机制。
该机制通过在 Token 维度进行高效压缩,从底层大幅降低了超长上下文处理对计算量与显存的占用需求,彻底解决了行业内长文本处理成本高昂的核心痛点。基于这一技术突破,1M 超长上下文能力将成为 DeepSeek 所有官方服务的标配,无需额外付费或申请特殊权限,即可实现百万字级别的长文档、多轮对话、复杂任务的端到端处理。
深度适配 Agent 生态,解锁复杂场景全能力
针对当前行业主流的 Agent 智能体产品(如 Claude Code、CodeBuddy 等),DeepSeek-V4 进行了全链路专项优化,打造了更适配智能体场景的模型能力:
- 原生支持非思考模式与深度思考模式双模式切换,兼顾简单任务的响应速度与复杂任务的推理深度;
- 在 API 接口中全新开放
reasoning_effort参数,支持用户根据任务复杂度自由调节思考强度(high/max 档位),显著提升代码生成、长文档解析、多步骤逻辑规划、复杂工具调用等场景的完成质量与稳定性。
访问与开源部署计划
体验与调用渠道
目前,用户可通过 DeepSeek 官方网站、官方 App 直接体验 DeepSeek-V4 系列模型的全能力,对应 API 接口已同步完成更新上线,可直接接入业务场景使用。
版本更迭通知
旧版
deepseek-chat与deepseek-reasoner模型名称,将于2026 年 7 月 24 日正式停用,开发者需在此之前完成模型接口的替换升级。开源地址与技术资料
DeepSeek-V4 系列模型已全量开源至 Hugging Face 与魔搭社区,配套技术报告同步披露于 Hugging Face 官方仓库中,开发者可自由下载、部署与二次开发:
- Hugging Face 开源地址:https://huggingface.co/collections/deepseek-ai/deepseek-v4
- 魔搭社区开源地址:https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
此次 DeepSeek-V4 的发布,不仅验证了开源大模型在超长上下文、Agent 智能体、深度推理等核心能力上,追赶甚至超越顶级闭源模型的可行性,更通过底层技术架构的突破,大幅降低了大模型高端能力的落地门槛,为 AGI 技术的普惠化进程提供了坚实的底座支撑。